
How to Configure Sources for Elvin Copilot
Elvin Copilot is designed to answer end-user questions by relying entirely on the knowledge sources you provide. Unlike general-purpose AI models such as ChatGPT, it does not depend on built-in world knowledge or pre-trained data. Instead, admins add and manage data sources that Elvin Copilot searches to generate responses for your clients.
The quality of answers will always match the quality and completeness of the sources you provide.
You retain full control over these sources: admins can add, edit, or remove them at any time, and changes take effect almost immediately. Importantly, Elvin Copilot does not train on your data, and the language models it uses run securely on dedicated Microsoft Azure cloud infrastructure, independent of providers like OpenAI or Google.

How to Configure Sources
To configure sources, navigate to Elvin Copilot from the menu bar, and under Connect select Knowledge Sources. You will see two sections:
- Internal Product Fruits Knowledge Base
- External Sources
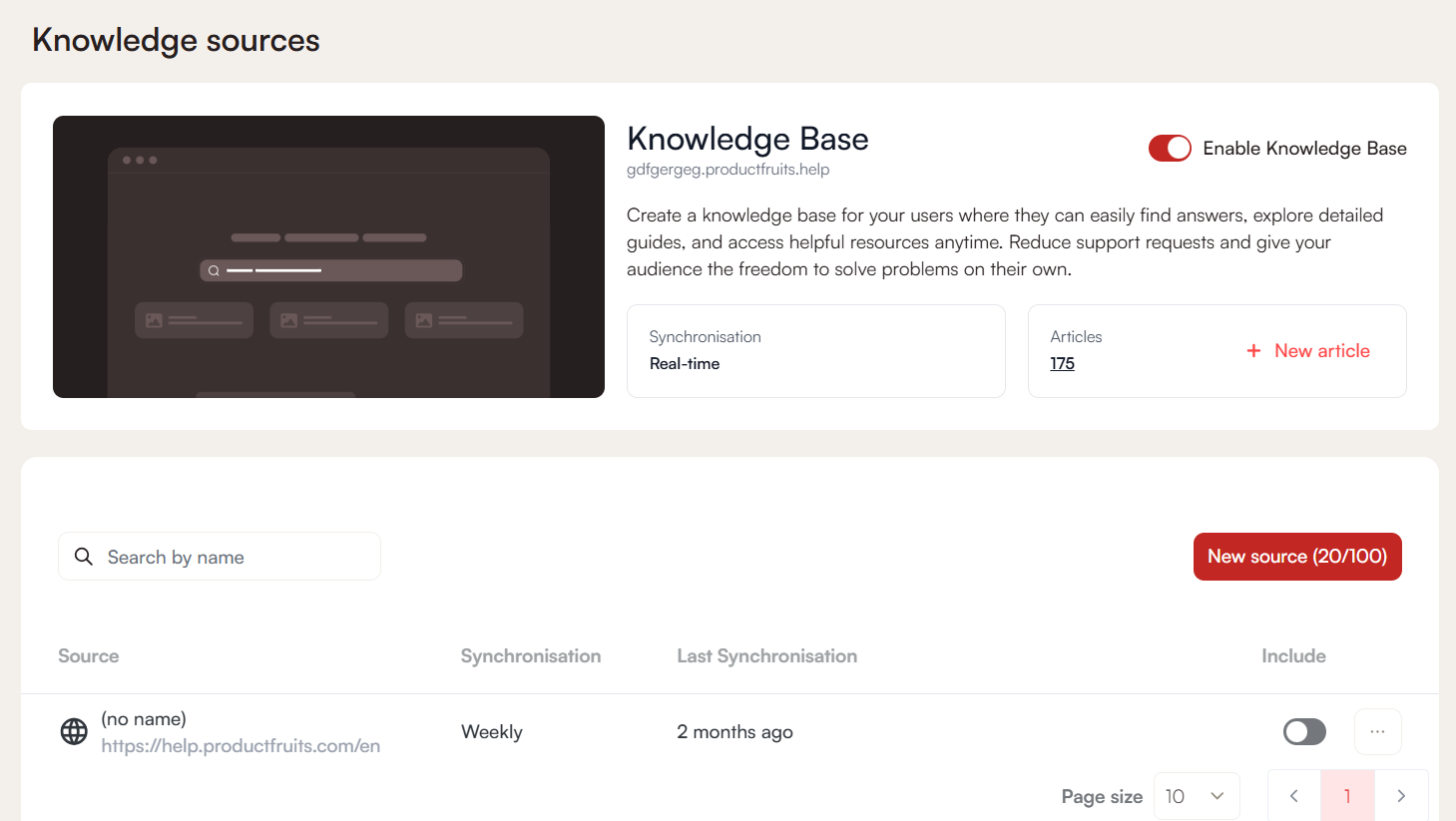
Knowledge Base as a Source
To use articles and documentation from your knowledge base, simply toggle on Enable Knowledge Base. Synchronization happens in real time, but an article must be published in order for Elvin to index it. As soon as you save changes, Elvin will automatically crawl the content.
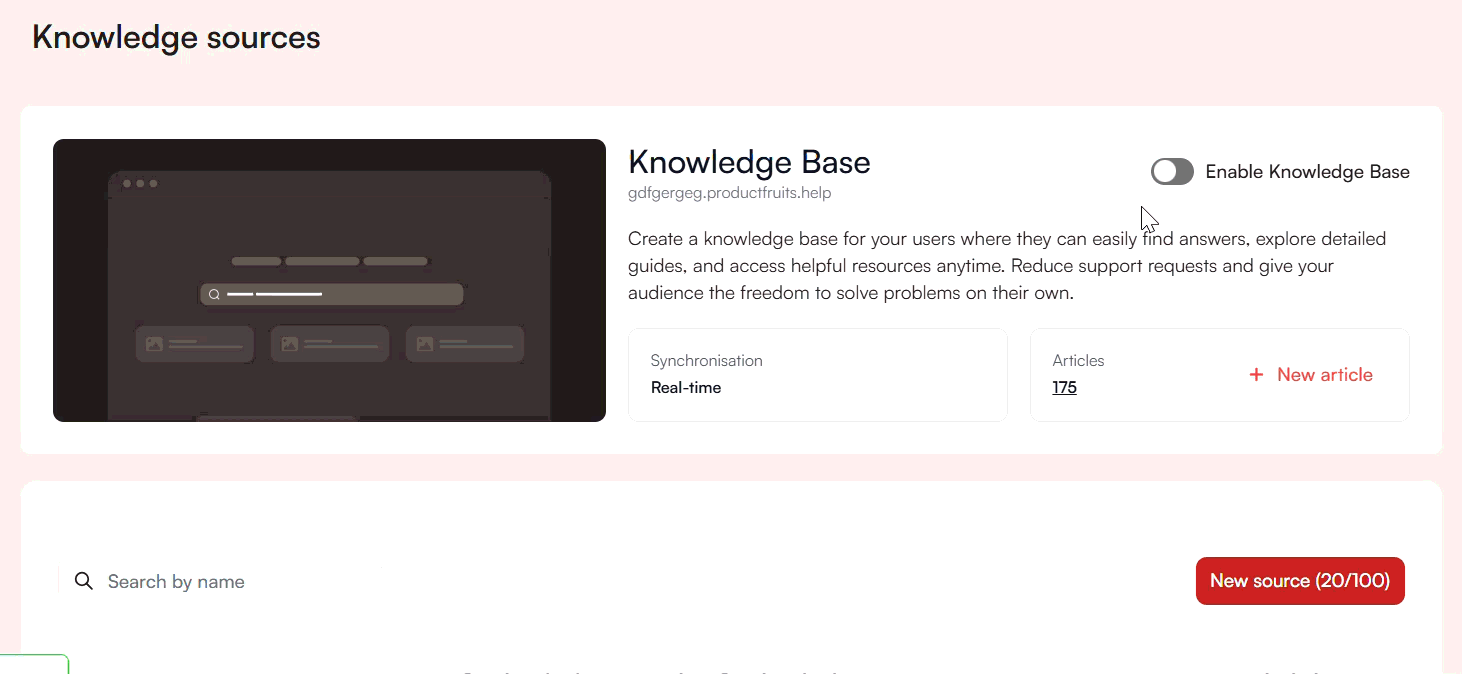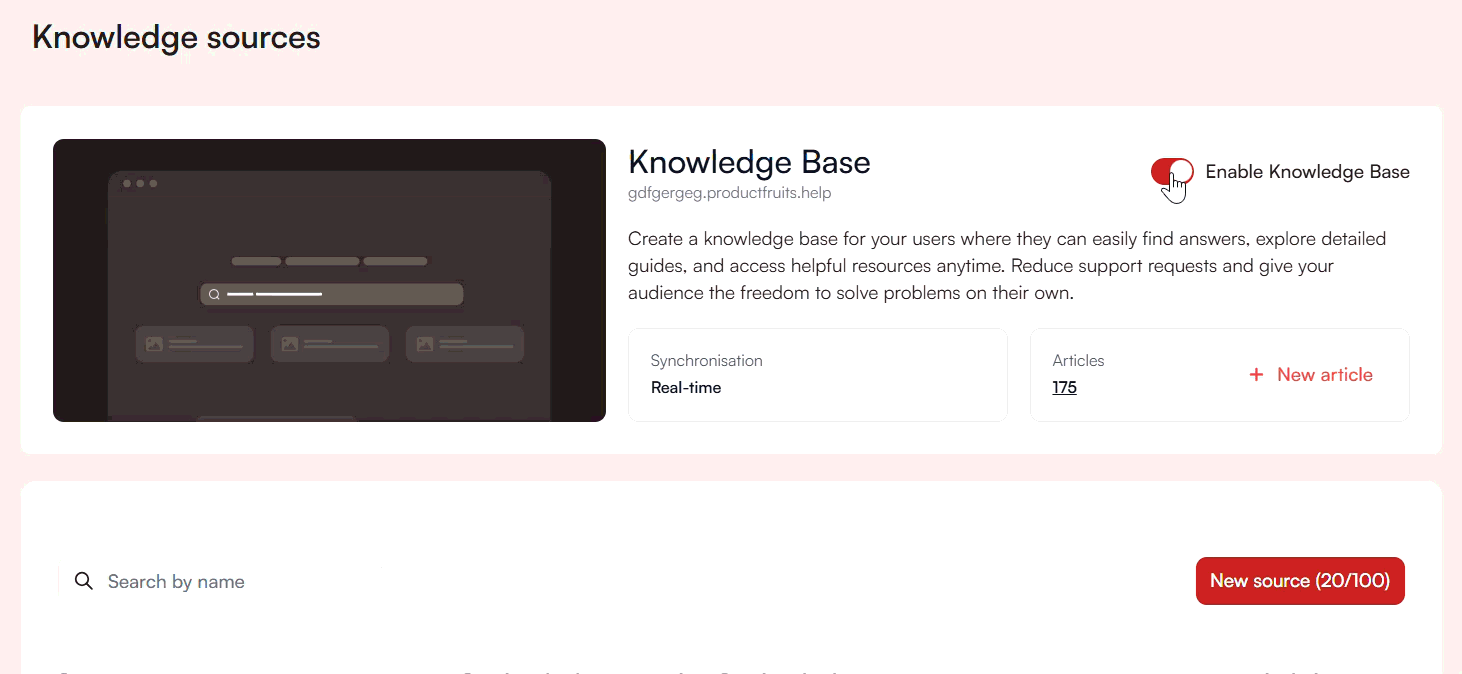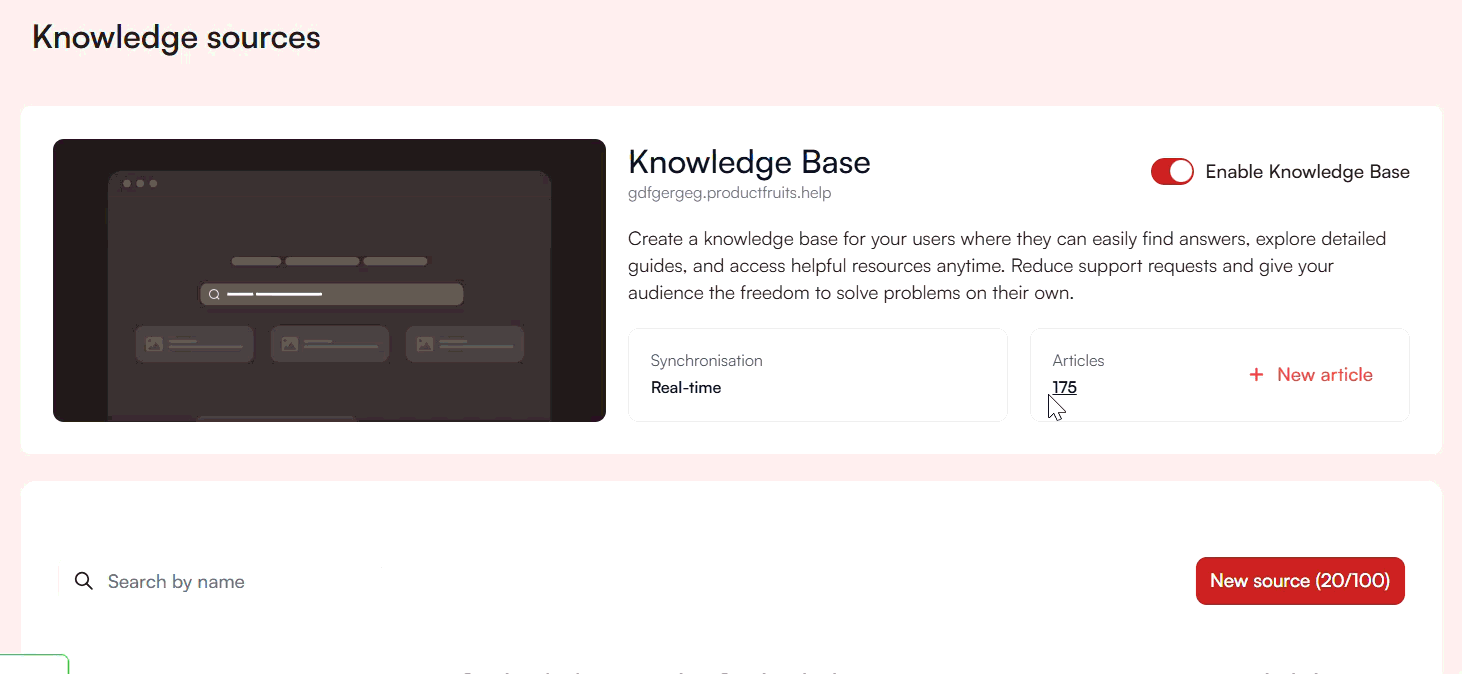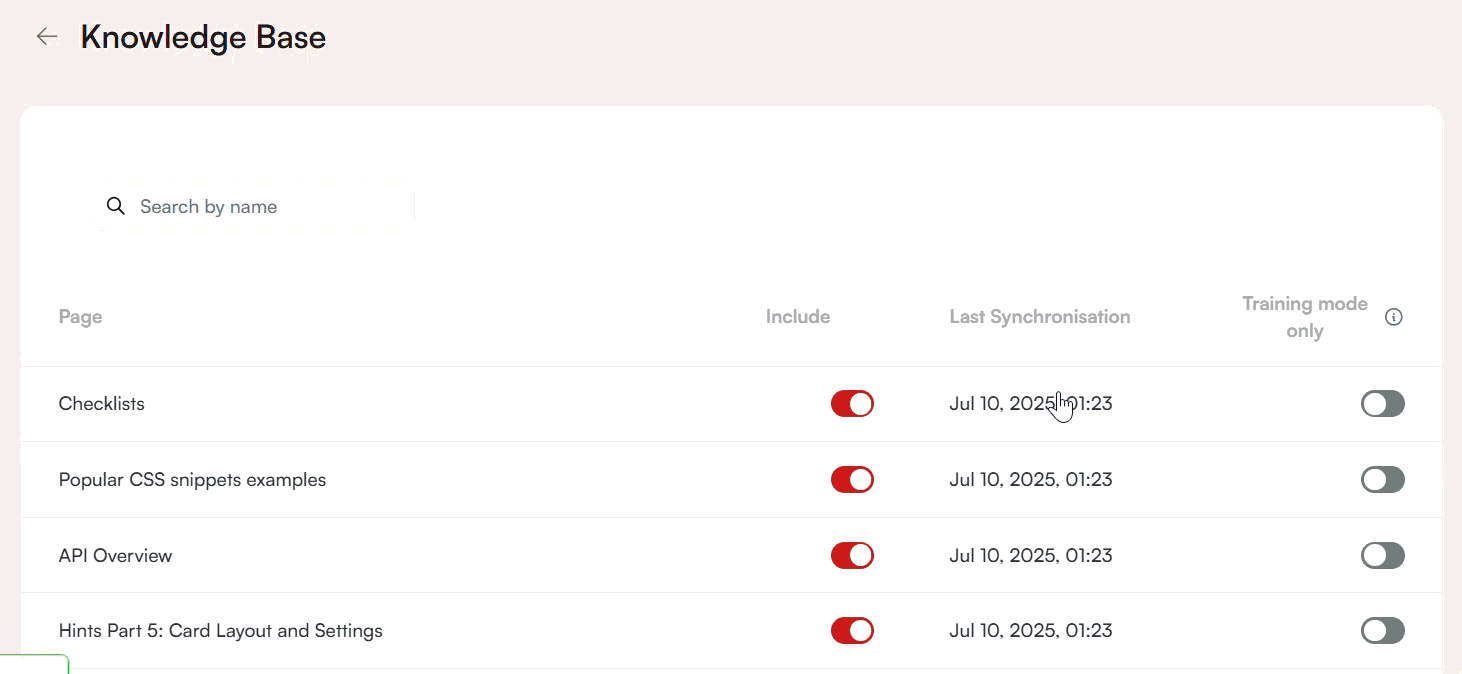
To manage these sources, click on the Articles box. This opens a table with the following information:
- Page: The name of the article.
- Include: A toggle to decide whether the article should be included in Copilot responses.
- Last Synchronization: The exact date and time the article was indexed.
- Training Mode Only: When enabled, Elvin uses the article to generate answers but does not cite it in end-user responses. The article is still listed under the Life Ring button.
Adding External Sources
In addition to knowledge base content, you can add websites or documents as external sources. The number of sources depends on your subscription plan and applies across all workspaces. You can check your exact source limits on the Pricing page.
Adding a Website as an External Source
To add a website, click New Source and select Website. Provide the website address and choose a crawler type:
- Basic crawler: For simple HTML sites.
- Crawler with JavaScript support: Uses a headless browser to handle modern, dynamic sites built with frameworks like React, Vue, or Angular.
- Crawler with proxy support: For advanced use cases where proxies are required.
For the last two options, you also need to provide a wait period in milliseconds.
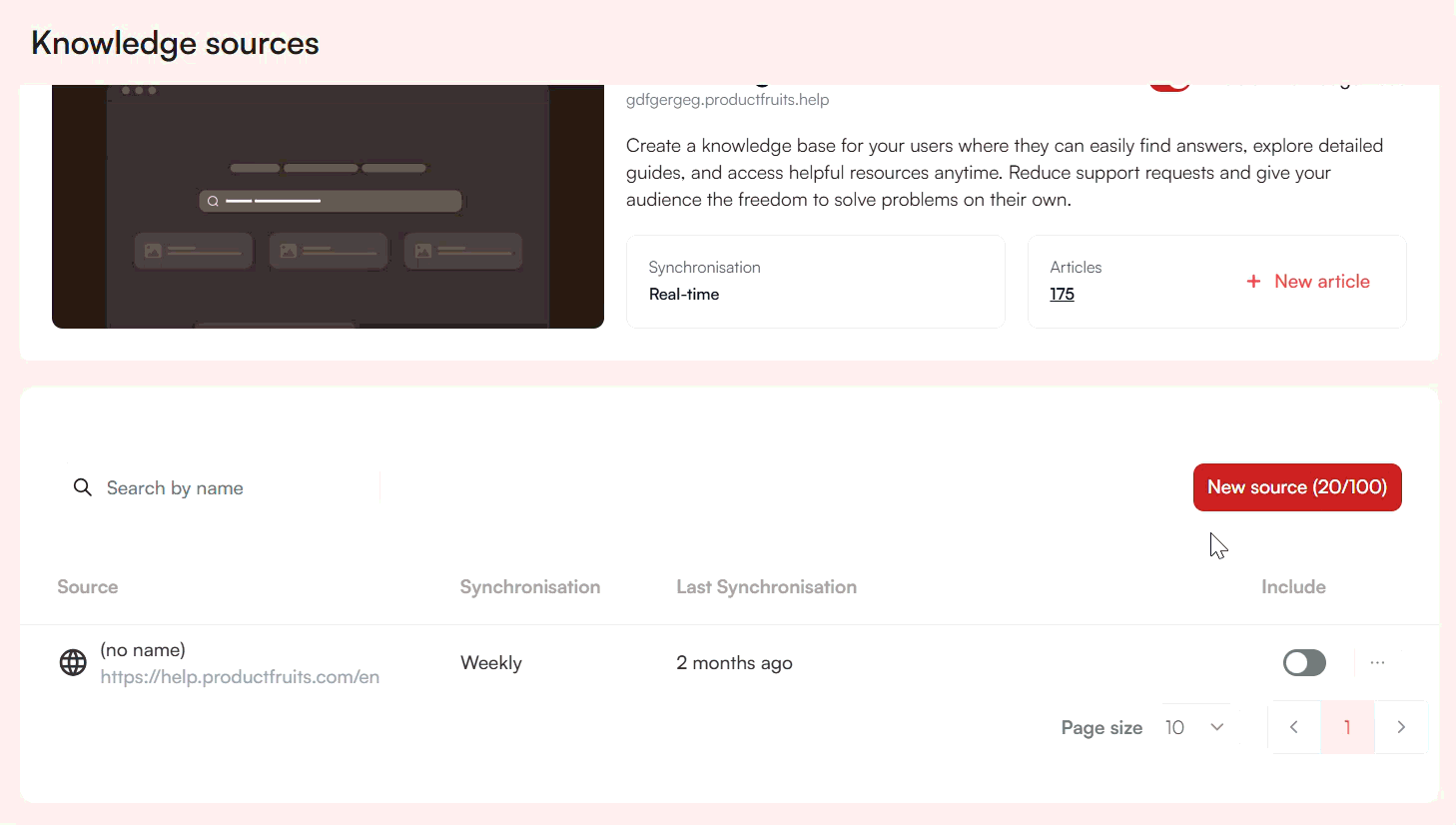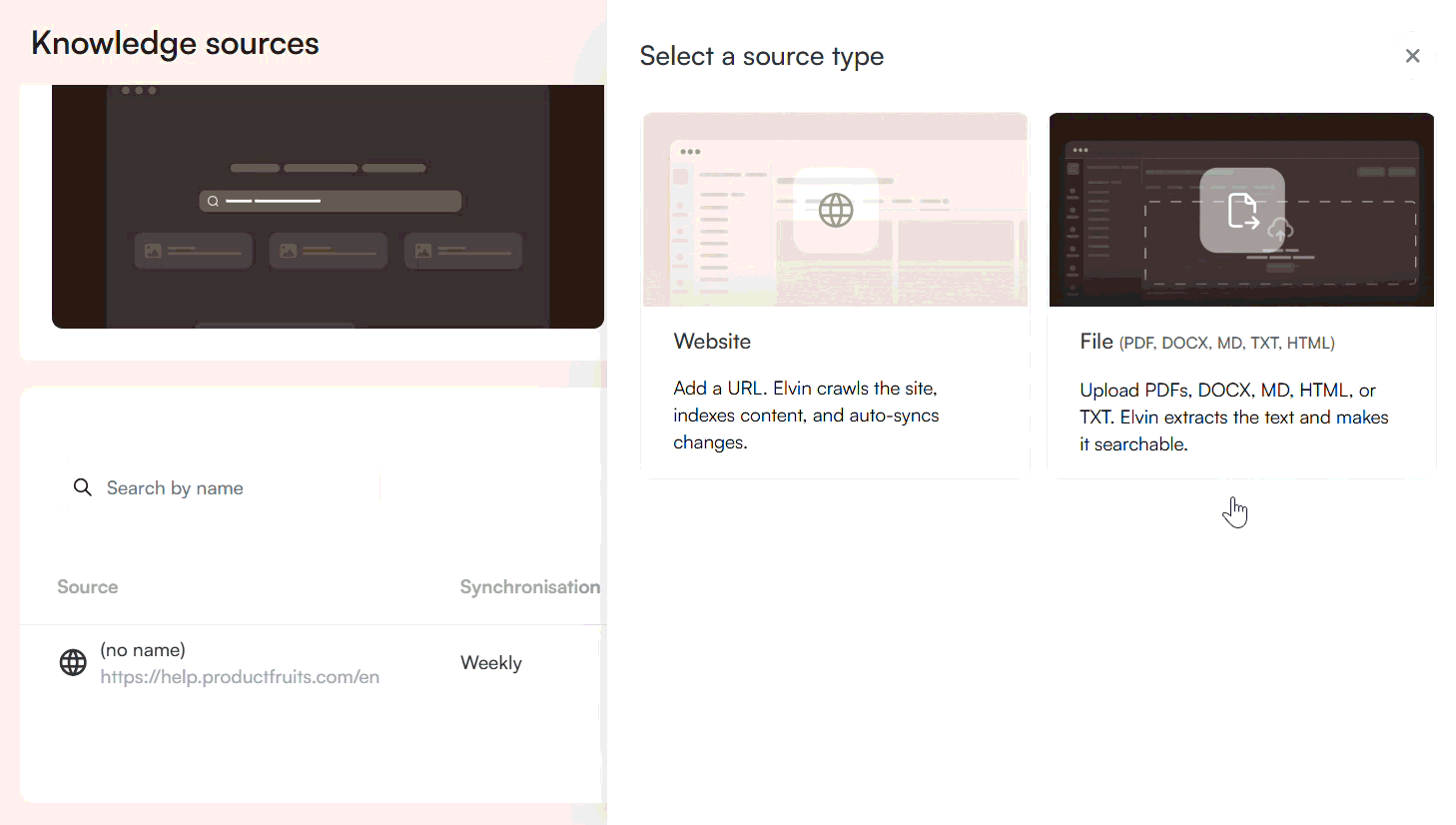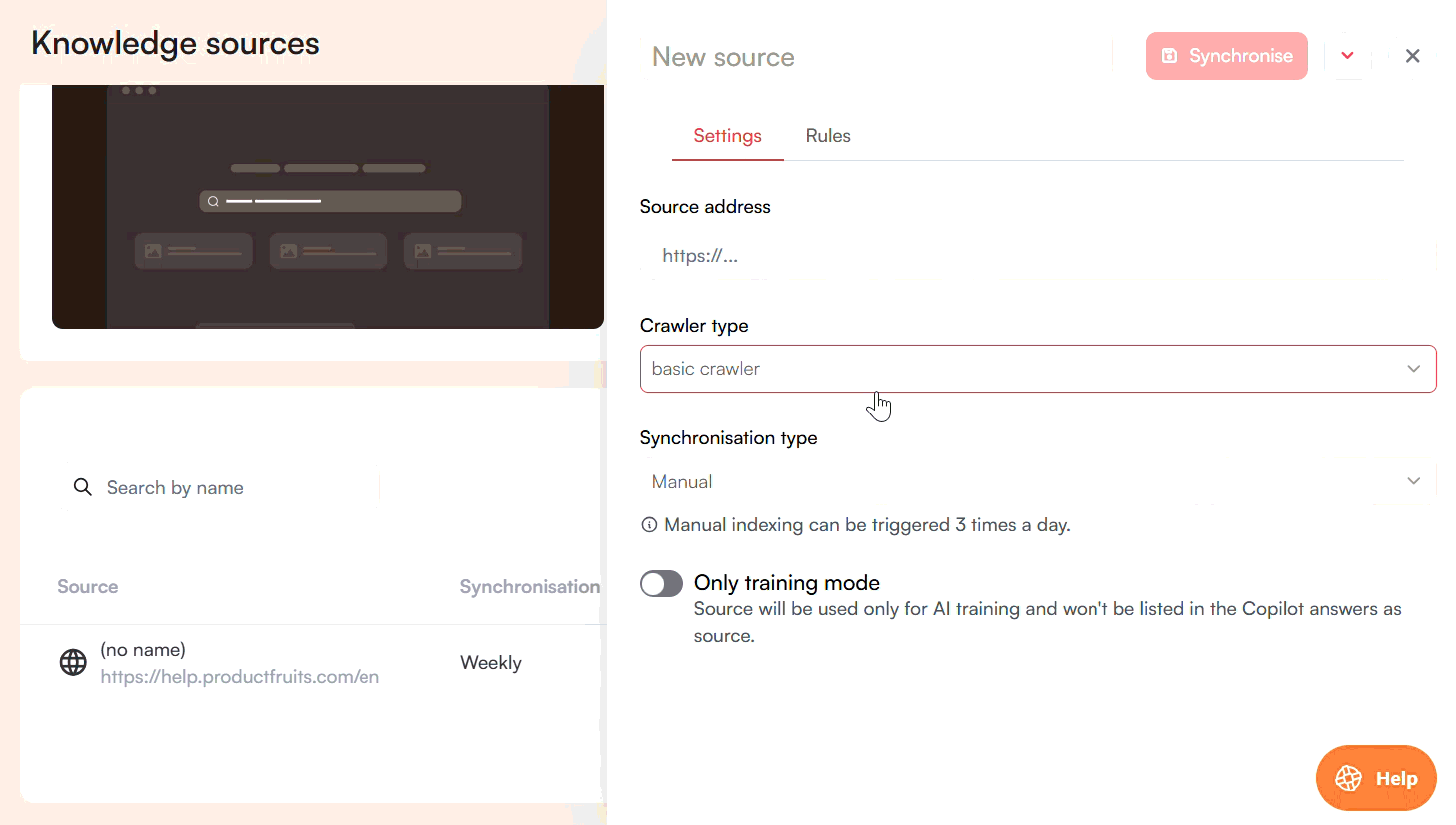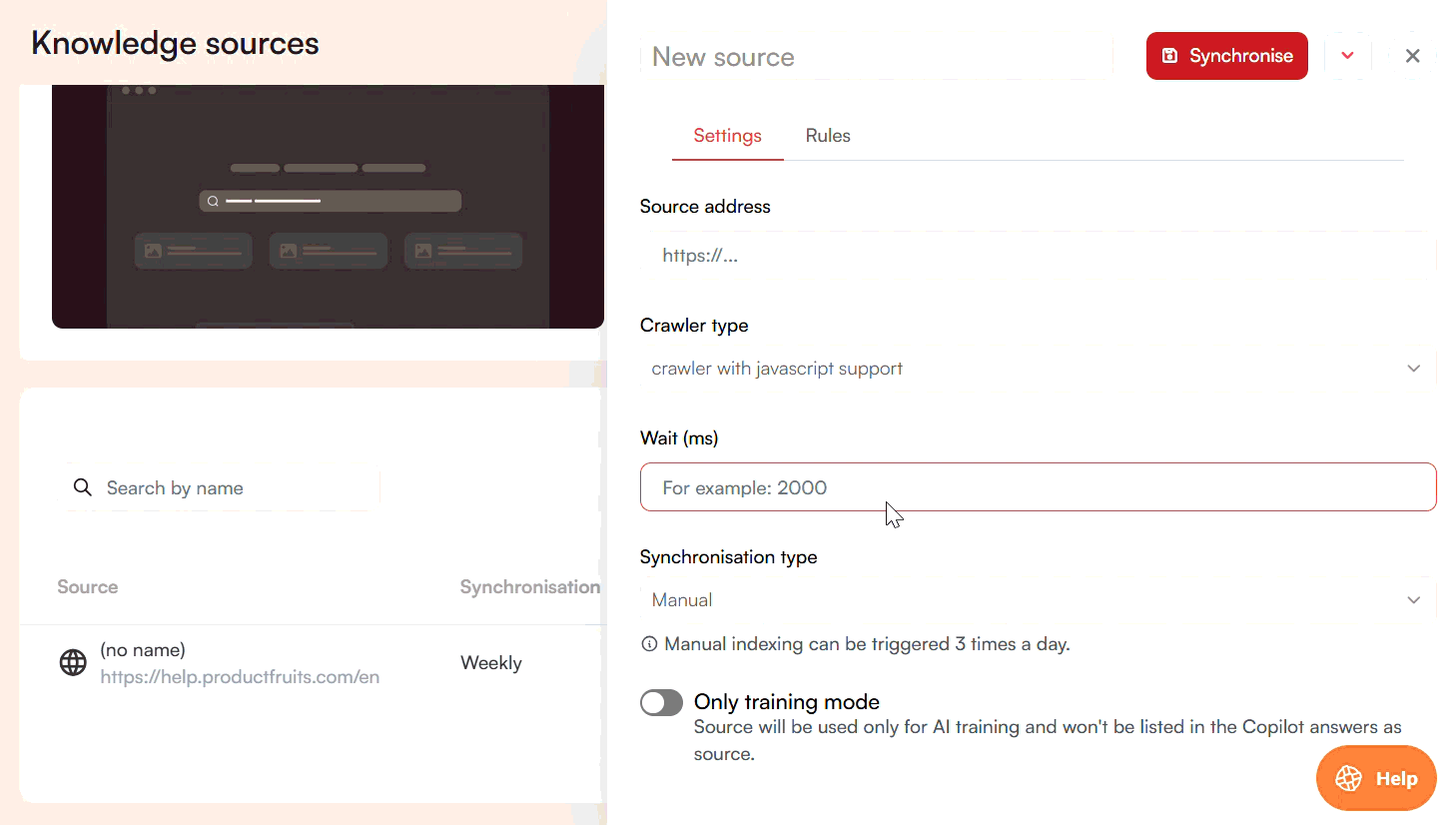
Website sources refresh automatically once per week, but you can trigger a manual refresh up to three times per day. Under the Rules tab, you can exclude specific paths from being crawled.
Some important details about the crawler:
- Each crawl is limited to 3,000 pages per domain (higher limits may be available depending on your plan).
- It respects
robots.txtdirectives and can also use sitemaps to discover additional URLs. - Crawls are rate-limited to avoid overwhelming servers.
- Authentication-gated or password-protected content cannot be indexed—only publicly accessible pages are supported.
- Crawls can be started manually at any time or left on the weekly automatic refresh.
As with knowledge base articles, you can enable training mode only so the website content is used for answer generation but not cited in user-facing responses.
Adding a Document as an External Source
You can also upload documents as knowledge sources. Supported formats include:
- DOCX (Microsoft Word)
- TXT (plain text)
- MD (Markdown)
- HTML (webpage file)
Each uploaded file counts as a single source. Files are indexed once at upload and are not automatically refreshed. If you update a document, you will need to delete the old version and upload the new one.
Keep in mind:
- The maximum file size is 50 MB per file.
- Only text is indexed, images inside PDFs or Markdown files are not processed.
 Need more help? Book an Elvin Demo with our team of AI experts.
Need more help? Book an Elvin Demo with our team of AI experts.